Deep Learning for autonomous driving
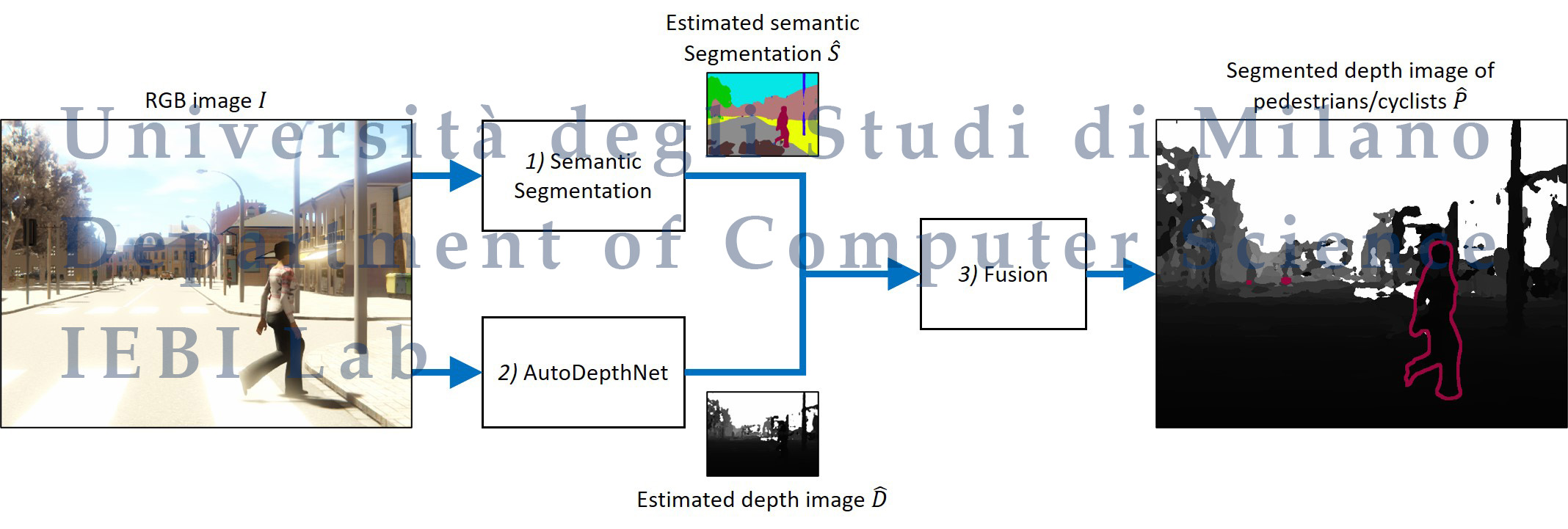
Driver attention assistance by pedestrian/cyclist distance estimation from a single RGB Image: A CNN-based semantic segmentation approach
Automotive companies are investing a relevant amount of resources for designing autonomous driving systems, driver assistance technologies, and systems for assessing the driver’s attention. In this context, an important application consists of technologies for estimating the object distances in the scene, with a specific focus on pedestrians/cyclists. These technologies are usually based on LiDAR scanners, which estimate a depth map representing the distances between the vehicle and the surrounding objects. To obtain highly accurate distance estimations in autonomous driving applications, methods based on Deep Learning (DL) and Convolutional Neural Networks (CNN) are being increasingly used, considering either RGB images or LiDAR scans. However, LiDAR scanners require dedicated sensors, high costs, and post-processing algorithms to estimate a dense depth map. In this paper, we propose the first method in the literature able to estimate the distances of pedestrians/cyclists from the vehicle by using only an RGB image and CNNs, without the need for any LiDAR scanner or any device designed for the three-dimensional reconstruction of the scene. We evaluated our approach on a public dataset of RGB images captured in an automotive scenario, with results confirming the feasibility of the proposed method.
Project page: https://iebil.di.unimi.it/DistPedCNN/index.htm
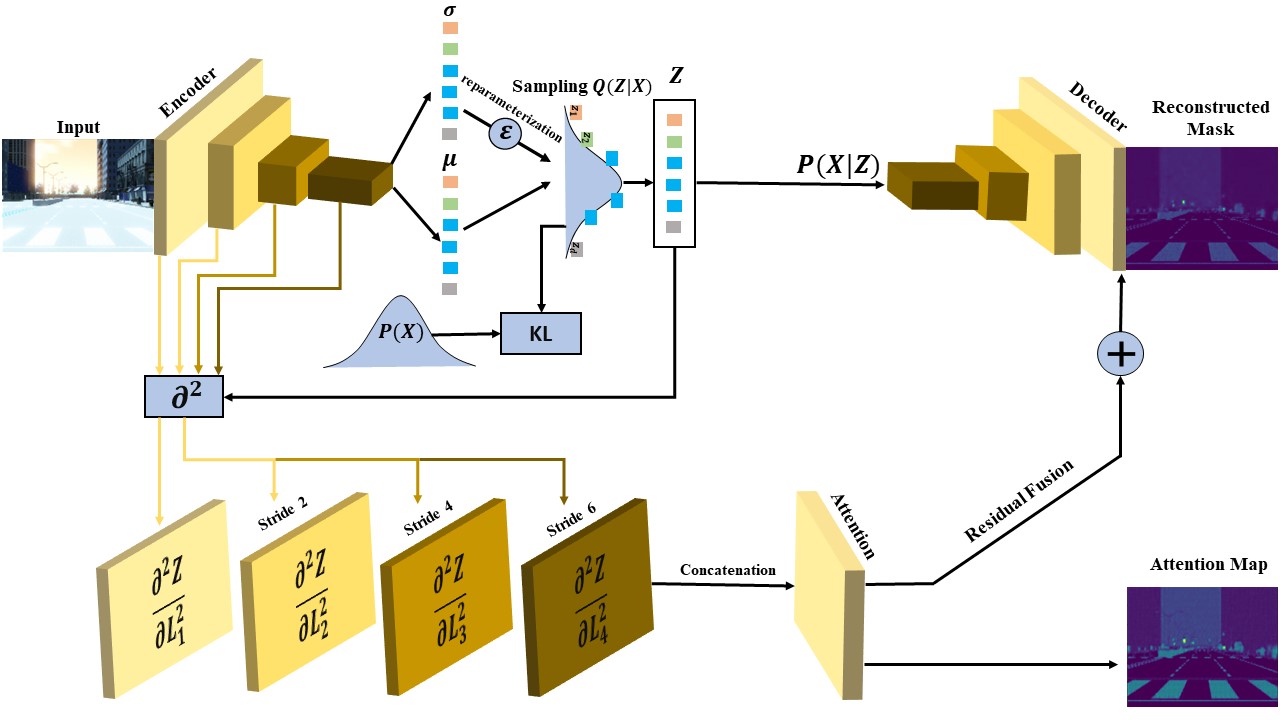
Towards explainable semantic
segmentation for autonomous
driving systems by multi-scale
variational attention
Explainable autonomous driving systems (EADS) are emerging recently as a combination of explainable artificial intelligence (XAI) and vehicular automation (VA). EADS explains events, ambient environments, and engine operations of an autonomous driving vehicular, and it also delivers explainable results in an orderly manner. Explainable semantic segmentation (ESS) plays an essential role in building EADS, where it offers visual attention that helps the drivers to be aware of the ambient objects irrespective if they are roads, pedestrians, animals, or other objects. In this paper, we propose the first ESS model for EADS based on the variational autoencoder (VAE), and it uses the multiscale second-order derivatives between the latent space and the encoder layers to capture the curvatures of the neurons’ responses. Our model is termed as Mgrad2VAE and is bench-marked on the SYNTHIA and A2D2 datasets, where it outperforms the recent models in terms of image segmentation metrics.
Project page: https://iebil.di.unimi.it/mgradvae/index.htm
References
-
F. Rundo, R. Leotta, V. Piuri, A. Genovese, F. Scotti, S. Battiato, "Intelligent road surface deep embedded classifier for an efficient physio-based car driver assistance", in Proc. of the 1st IEEE Int. Conf. on Autonomous Systems (ICAS 2021), Montreal, QC, Canada, pp. 1-5, August 11-13, 2021. ISBN: 978-1-7281-7289-7. [DOI: 10.1109/ICAS49788.2021.9551124][PDF]
-
M. Abukmeil, A. Genovese, V. Piuri, F. Rundo, F. Scotti, "Towards explainable semantic segmentation for autonomous driving systems by multi-scale variational attention", in Proc. of the 1st IEEE Int. Conf. on Autonomous Systems (ICAS 2021), Montreal, QC, Canada, pp. 1-5, August 11-13, 2021. ISBN: 978-1-7281-7289-7. [DOI: 10.1109/ICAS49788.2021.9551172][PDF]
-
A. Genovese, V. Piuri, F. Rundo, F. Scotti, C. Spampinato, "Driver attention assistance by pedestrian/cyclist distance estimation from a single RGB Image: A CNN-based semantic segmentation approach", in Proc. of the 22nd IEEE Int. Conf. on Industrial Technology (ICIT 2021), Valencia, Spain, pp. 875-880, March 10-12, 2021. ISBN: 978-1-7281-5730-6. [DOI: 10.1109/ICIT46573.2021.9453567][PDF]
-
F. Rundo, R. Leotta, F. Trenta,
G. Bellitto, F. Salanitri,
V. Piuri, A. Genovese,
R. Donida Labati, F. Scotti,
C. Spampinato, S. Battiato, "Advanced car driving assistant system: A deep non-local pipeline combined with 1D dilated CNN for safety driving", in Proc. of the 2021 Int. Conf. on Image Processing and Vision Engineering (IMPROVE 2021), pp. 81-90, April 28-30, 2021. ISBN: 978-989-758-511-1. [DOI: 10.5220/0010381000810090][PDF]